
As data grows in volume, variety, and velocity, traditional systems are no longer enough. Big Data Architecture provides the blueprint for managing, processing, and analyzing massive datasets efficiently. It combines advanced storage, distributed computing, and real-time processing to turn complex data into meaningful insights.
Why Big Data Architecture?
-
Scalable Processing – Handle terabytes to petabytes of structured and unstructured data.
-
Real-Time Insights – Process streaming data for faster decision-making.
-
Cost Efficiency – Optimize infrastructure with cloud-native and distributed frameworks.
- Integration – Seamlessly connect data sources, pipelines, and analytics tools.
Key Components
WHAT IS BIG DATA ARCHITECTURE
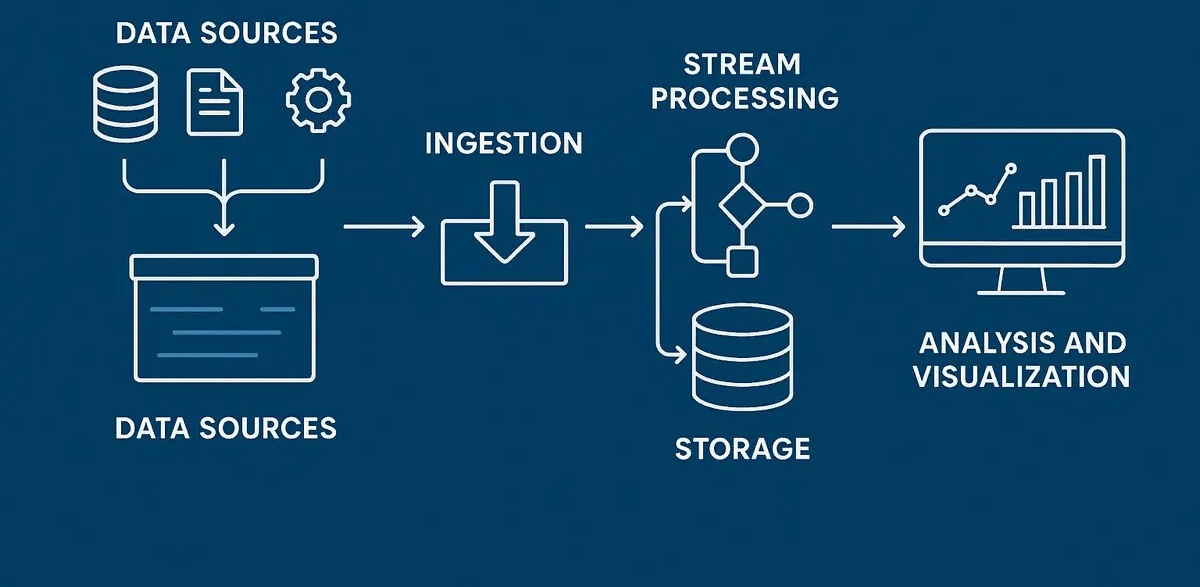
Core Components of Big Data Architecture
Includes structured (databases, ERP, CRM) and unstructured data (logs, IoT sensors, social media, images).Data can originate from cloud applications, on-premise systems, or external APIs.
Responsible for collecting and importing raw data into the system.Tools like Apache , Azure Data Factory.
Stores massive volumes of raw and processed data for analysis. Can include data lakes, data warehouses, or hybrid storage systems. Tools like Amazon S3, Azure Data Lake, Google Cloud Storage.
Handles real-time and batch data processing for analytics. Tools like Apache, Databricks.
Transforms processed data into business insights. Tools like Power BI, Tableau.
Ensures compliance, quality, and privacy through role-based access, encryption, and metadata management. Tools like Apache.
Key Features of Big Data Architecture
-
Scalability: Seamlessly manage data growth across systems and regions.
-
Real-Time Processing: Analyze data as it arrives for faster decision-making.
-
Real-Time Processing: Analyze data as it arrives for faster decision-making.
-
Integration: Connects diverse data sources across cloud and on-premise systems.
- Fault Tolerance: Ensures high availability and data reliability.
- Security & Compliance: Protects sensitive information and maintains governance standards.